逆轉大老2是大老2遊戲的改良玩法,靈感是來自小時候在掌機上玩過的某個遊戲。
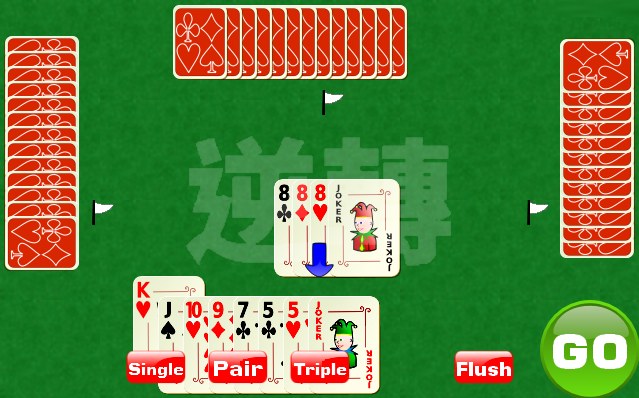
逆轉大老2遊戲規則-
* 遊戲使用整副牌52張+2張鬼牌。
* 牌型包含(單張,對子,三條,四條,同花順),同花順最少3張沒有張數上限。
* 只比數字大小,不比花色。
* 數字3最小,依次為3<4<5<6<7<8<9<10<J<Q<K<A<2<鬼牌最大。
* 每次打出四條時大小逆轉2變最小,依次為2<A<K<Q<J<10<9<8<7<6<5<4<3<鬼牌還是最大。
* 鬼牌可以當作任意牌和其它牌配對。例如:鬼牌+2=2一對,方塊2+鬼牌+方塊4=234順子。
* 遊戲開始,手上有梅花3的玩家先出手,可以打包含梅花3的任意牌型的牌。
* 下家要跟上家打出同樣的牌型的牌,無法出牌則PASS。
* 若三家都PASS,則有得到先手權可以再打出新的任意牌型的牌。
* 三家把手上的牌都打完只剩一家未完時,牌局結束。
<<Free Android Download>>
;
目前遊戲內容定義了4個不同分級的AI,不過目前第4級AI還沒實作,等未來視情況再看看...
AI1:簡單的規則讓AI動起來
逆轉大老2遊戲規則-
* 遊戲使用整副牌52張+2張鬼牌。
* 牌型包含(單張,對子,三條,四條,同花順),同花順最少3張沒有張數上限。
* 只比數字大小,不比花色。
* 數字3最小,依次為3<4<5<6<7<8<9<10<J<Q<K<A<2<鬼牌最大。
* 每次打出四條時大小逆轉2變最小,依次為2<A<K<Q<J<10<9<8<7<6<5<4<3<鬼牌還是最大。
* 鬼牌可以當作任意牌和其它牌配對。例如:鬼牌+2=2一對,方塊2+鬼牌+方塊4=234順子。
* 遊戲開始,手上有梅花3的玩家先出手,可以打包含梅花3的任意牌型的牌。
* 下家要跟上家打出同樣的牌型的牌,無法出牌則PASS。
* 若三家都PASS,則有得到先手權可以再打出新的任意牌型的牌。
* 三家把手上的牌都打完只剩一家未完時,牌局結束。
<<Free Android Download>>
;
目前遊戲內容定義了4個不同分級的AI,不過目前第4級AI還沒實作,等未來視情況再看看...
AI1:簡單的規則讓AI動起來
- 手上有梅花作為開局者,出單張梅花3。
- 順位的情況,出最小的單張牌。
- 下手跟著上手出同類牌組,數字>上手即可。
- 無牌可出PASS。
- 重覆2-4,直到打完手上牌為止。
AI2:計算牌組分數決定出什麼牌
- 根據已經打出的桌面上的牌和自己手上的牌來計算每張牌的分數來估計自己手上所有牌的分數(被蓋牌的機率),若自己手上有二張3和一張5,且還有一張4和二張6未出(共三張牌未出),則:
- 3的分數 = (可蓋過3的牌數)/(總牌數) = (1(1張5) + 2(2張6)) / 3
- 5的分數 = (可蓋過5的牌數)/(總牌數) = 2(2張6) / 3
- 分數的調整:每張牌計算出分數後再作調整
- 若這張牌可以是對子(/2)
- 若這張牌可以是三條(/3)
- 若這張牌可以是順子(/3.5)
- 若這張牌可以是四條(/4)
- 自己手上這把牌的總分 = 3的分數/2(對子) + 3的分數/2(對子) + 5的分數 = (3/3)/2 + (3/3)/2 + 2/3
- 計算所有可能牌型各別打出後的牌組分數,得分最低分者為要打的牌,也就是儘可能讓自己手上的牌被蓋牌的綜合機率最小。
- 若找不到最低分的牌,則打第一張單張牌,或無法出牌則PASS。
AI3:AI2的微調
以上3種版本的AI,AI1不用說最笨了,只是一開始開發時讓AI可以先動起來的簡單作法。AI2和AI3就利害多了,牌局的開局和中局階段都有不錯的表現,但殘局階段少了人類策略手段就不太行了。尤其AI3因為以剩餘牌數作參數,所以一昧的表現出猛烈攻勢,不是很快clear就是到殘局好牌都出盡了,剩下難打出的小牌。
- 以AI2為基礎,計算所有可能牌型打出後的牌組分數,得分最低分者或者剩餘牌的張數為最少者為要打的牌。
- 計算出這張牌的分數(被壓過的機率)若大於0.06則牌數+1,否則不計。
- 若找不到最低分的牌,則打第一張單張牌,或無法出牌則PASS。
以上3種版本的AI,AI1不用說最笨了,只是一開始開發時讓AI可以先動起來的簡單作法。AI2和AI3就利害多了,牌局的開局和中局階段都有不錯的表現,但殘局階段少了人類策略手段就不太行了。尤其AI3因為以剩餘牌數作參數,所以一昧的表現出猛烈攻勢,不是很快clear就是到殘局好牌都出盡了,剩下難打出的小牌。
留言
張貼留言