前面我們透過手工的方式實作了一個簡易的算式計算機,現在我們要開始使用工具來作同樣的事,比較看看手工和使用工具有什麼不同的差別。首先要介紹的就是lex&yacc。
lex & yacc
lex(Lexical Analyzar)及yacc(Yet Another Compiler Compiler)是用來輔助程式設計師製作語法剖析器的程式工具。lex的工作就是幫助我們將輸入的資料文字串流分解成一個個有意義的token,而yacc的工作就是幫我們分析這些token和我們定義的規則作匹配。下圖中所表示的是使用lex及yacc的一般工作流程。
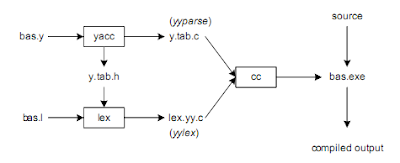
首先看到yacc會讀入一個.y檔案,這裡.y檔案的內容就是我們使用類似(E)BNF語法定義的語法規則,yacc會分析這些語法規則後,幫我們產生可以用來解析這些規則的程式碼,而這個檔案一般名稱預設為y.tab.c,產生的程式碼裡面最重要的一個的函式叫作yyparse。
同yacc類似,lex也會讀入一個.l的檔案,這個檔案裡面定義的是如何從文字流裡解出token的規則,使用的方法是常規表示式(regular expression)。在圖的左側中間我們還可以看到有一個叫作y.tab.h的檔案從yacc產生出來並餵給lex作輸入,這個檔案是yacc根據在讀入的.y檔裡面所定義的token代號所產生出來的一個header,這樣yacc及lex產生出來的程式碼裡面就可以使用共通定義的代碼而不必各寫個的。lex分析過.l檔案後也會產生一個一般預設叫作lex.yy.c的原始碼檔案,裡頭最重要的一個函式叫作yylex。
最後,我們把yacc產生出來的y.tab.c還有lex產生出來的lex.yy.c,以及其它我們自己撰寫的原始碼檔案一起拿來編譯再作連結,最後產生出來的就是一個可以用來解析我們定義的語法的解析器工具。以上是整個lex及yacc的使用流程概觀。
常規表示式
在正式使用lex之前,我們首先來對常規表示法作一個基本的認識。常規表示法是一種用來表示字串樣式(pattern)的中繼語言,就好比前文所介紹的(E)BNF表示式一樣,都是用來描述其它語言的語言,只不過用途不太一樣罷了。
常規表示式使用一些中繼符號(meta-symbol)以及ASCII字元定義字串樣式,以下列出一些常規表示式所使用的符號。
lex
現在要開始使用lex來協助我們寫個簡單的字彙剖析器作練習,這個範例可以作簡單的計算字元數、字數及行數。在那之前我們先來看看前面提到過的要輸入給lex的定義檔案內容是長什麼樣子。如下所示,我們可以看到一份定義檔案內容以符號%%分為三大區塊。
樣式區塊是主要的重點區塊,裡面條列的是我們剛剛學習的使用常規表示式定義的樣式以及對應的動作程式碼,動作程式碼的作用等到稍後我們真正見到時再作說明。而程式碼區塊和定義區塊一樣,放置的也是我們自己的程式碼。lex在最後為我們產生字彙剖析器的程式碼時也會原封不動的複製過去,而不作任何處理。
接下來我們可以寫下計算字數行數範例所需要的定義檔。
接著在樣式區塊裡面定義了三個樣式,根據我們在上一節裡面學到的對於常規表示式的知識,我們可以知道這三條樣式所代表的意義。
以\n這條樣式來說明,如果樣式匹配,則程式碼{ nline++; nchar++; }會被執行。注意到這裡的大括號,假如動作程式碼只有一行的話,則大括號是可有可無的,像是第三條樣式。但我們一律還是都寫上大括號以免有所遺漏,同時也要注意的是不管動作程式碼有幾條指令,全部都要寫在同一行裡面。
最後是程式碼區塊。這區塊裡有個main進入點,第一行指令呼叫了yylex這個函式。在前面的介紹中,我們知道yylex是由lex自動幫我們產生的函式,這個函式的工作就是幫我們作字彙剖析,一直到結束後才會返回。返回之後,我們再把計算的字元數、字數以及行數列印到畫面上。
看過這個簡單的範例之後,是不是對於lex是如何運作以及怎麼使用lex有點概念了。
yacc
yacc必須搭配lex一起使用,因為yacc主要的工作是作語法分析,而構成語法句子的token是由lex負責分析比對。和上一節同樣,我們透過一個簡單的範例來學習如何使用yacc。這個範例我們要作的是,能從輸入串流中的每一行文字裡讀取0個或1個以上的數字,如果有超過1個以上的數字,則每個數字需以逗號分開,最後再把所有數字相加的結果列印到畫面上,直到結束輸入為止。
首先我們第一步驟是使用EBNF表示式把規則寫出來。
我們現在要注意的是在樣式的右側的動作程式碼。和lex定義檔裡的動作程式碼一樣,我們統一使用大括號將動作指令括起來。在動作程式碼裡面我們可以看到像$1、$2還有$$這樣奇怪的東西。在動作程式碼裡的這幾個符號是對應到樣式裡面的符號值,從左邊開始算來,第一個符號叫作$1,第二個叫$2,依此類推。而樣式左側,也就是樣式冒號的左側值則以$$表示。
因此,我們在lines樣式裡的$2就對應integers。預設情形下,符號值的型別是整數,當然我們也可以使用其它型別的符號值,不過這不是我們要談的重點,有興趣的話請參考lex/yacc相關書籍資料。lex定義檔內容我們就不再表列出來,可以自行參考範例內容。
實作
了解lex及yacc的使用後,我們就可以使用lex及yacc來協助我們實作算式計算機了。以下表列出yacc的算式計算機實作定義檔內容。
lex & yacc
lex(Lexical Analyzar)及yacc(Yet Another Compiler Compiler)是用來輔助程式設計師製作語法剖析器的程式工具。lex的工作就是幫助我們將輸入的資料文字串流分解成一個個有意義的token,而yacc的工作就是幫我們分析這些token和我們定義的規則作匹配。下圖中所表示的是使用lex及yacc的一般工作流程。

首先看到yacc會讀入一個.y檔案,這裡.y檔案的內容就是我們使用類似(E)BNF語法定義的語法規則,yacc會分析這些語法規則後,幫我們產生可以用來解析這些規則的程式碼,而這個檔案一般名稱預設為y.tab.c,產生的程式碼裡面最重要的一個的函式叫作yyparse。
同yacc類似,lex也會讀入一個.l的檔案,這個檔案裡面定義的是如何從文字流裡解出token的規則,使用的方法是常規表示式(regular expression)。在圖的左側中間我們還可以看到有一個叫作y.tab.h的檔案從yacc產生出來並餵給lex作輸入,這個檔案是yacc根據在讀入的.y檔裡面所定義的token代號所產生出來的一個header,這樣yacc及lex產生出來的程式碼裡面就可以使用共通定義的代碼而不必各寫個的。lex分析過.l檔案後也會產生一個一般預設叫作lex.yy.c的原始碼檔案,裡頭最重要的一個函式叫作yylex。
最後,我們把yacc產生出來的y.tab.c還有lex產生出來的lex.yy.c,以及其它我們自己撰寫的原始碼檔案一起拿來編譯再作連結,最後產生出來的就是一個可以用來解析我們定義的語法的解析器工具。以上是整個lex及yacc的使用流程概觀。
常規表示式
在正式使用lex之前,我們首先來對常規表示法作一個基本的認識。常規表示法是一種用來表示字串樣式(pattern)的中繼語言,就好比前文所介紹的(E)BNF表示式一樣,都是用來描述其它語言的語言,只不過用途不太一樣罷了。
常規表示式使用一些中繼符號(meta-symbol)以及ASCII字元定義字串樣式,以下列出一些常規表示式所使用的符號。
. 表示除了換行字元以外的所有其它字元。底下列出一些範例。範例的左邊是樣式,右邊是符合樣式的字串。
\n 表示一個換行字元。
* 表示左方的字元或樣式可以是0個或多個。
+ 表示左方的字元或樣式可以是1個以上。
? 表示左方的字元或樣式可以是0個或1個(可有可無)。
^ 表示是在一行的開頭。或者在方括號內表示[不包含]。
$ 表示是在一行的最後。
a | b 表示為a或b二者選一。
(ab)+ 小括號裡表示為一個子樣式,表示為有1個以上的ab組合。
"a+b" 字串常量"a+b"。
[] 一組字元,表示為這組字元當中的任一個。
abc abc看過這幾個簡單的範例之後,相信對於常規表示式有了一個基本的認識。
abc* ab abc abcc abccc ...
abc+ abc abcc abccc ...
a(bc)+ abc abcbc abcbcbc ...
a(bc)? a abc
[abc] a b c (三者其中之一)
[a-z] 任何a到z之間的字元
[a\-z] a - z (三者其中之一)
[-az] - a z (三者其中之一)
[A-Za-z0-9]+ 1個以上的大小寫英文字母及數字組成的字串
[ \t\n]+ 1個以上的空白字元 (包含空白,跳鍵及換行字元)
[^ab] 除了a及b以為的任何字元
[a^b] a ^ b (三者其中之一)
[a|b] a | b (三者其中之一)
a|b a或b其中一個
lex
現在要開始使用lex來協助我們寫個簡單的字彙剖析器作練習,這個範例可以作簡單的計算字元數、字數及行數。在那之前我們先來看看前面提到過的要輸入給lex的定義檔案內容是長什麼樣子。如下所示,我們可以看到一份定義檔案內容以符號%%分為三大區塊。
%{
... 定義 ...
%}
%%
... 樣式 ...
%%
... 程式 ...定義區塊裡面放的是我們的程式碼,我們可以把和應用程式相關的定義或宣告放在這個區塊裡面。lex載入定義檔為我們產生字彙剖析器的程式碼時,會原封不動的把這一區塊個的程式碼複製過去,而不會對這部份程式碼作任何處理。樣式區塊是主要的重點區塊,裡面條列的是我們剛剛學習的使用常規表示式定義的樣式以及對應的動作程式碼,動作程式碼的作用等到稍後我們真正見到時再作說明。而程式碼區塊和定義區塊一樣,放置的也是我們自己的程式碼。lex在最後為我們產生字彙剖析器的程式碼時也會原封不動的複製過去,而不作任何處理。
接下來我們可以寫下計算字數行數範例所需要的定義檔。
%{
int nchar, nword, nline;
%}
%%
\n { nline++; nchar++; }
[^ \t\n]+ { nword++, nchar += yyleng; }
. { nchar++; }
%%
int main(void)
{
yylex();
printf("%d\t%d\t%d\n", nchar, nword, nline);
return 0;
}在這份定義文件內,我們看到在定義區塊裡面有一行C語言的變數宣告,宣告了三個整數變數,nchar、nword及nline,分別用來代表接下來我們要計算的字元數、字數以及行數。接著在樣式區塊裡面定義了三個樣式,根據我們在上一節裡面學到的對於常規表示式的知識,我們可以知道這三條樣式所代表的意義。
\n 換行字元我們現在要注意的是在樣式常規表示代的右邊以大括號括起來的程式碼,這就是前頭我們有提到過的動作程式碼。這是在字彙剖析器在分析字串樣式匹配時,若樣式符合且樣式有指定動作程式碼,也就是在樣式右側的程式碼,則這段程式碼就會被執行。
[^ \t\n]+ 1個以上的非空白字元
. 換行字元之外的所有字元
以\n這條樣式來說明,如果樣式匹配,則程式碼{ nline++; nchar++; }會被執行。注意到這裡的大括號,假如動作程式碼只有一行的話,則大括號是可有可無的,像是第三條樣式。但我們一律還是都寫上大括號以免有所遺漏,同時也要注意的是不管動作程式碼有幾條指令,全部都要寫在同一行裡面。
最後是程式碼區塊。這區塊裡有個main進入點,第一行指令呼叫了yylex這個函式。在前面的介紹中,我們知道yylex是由lex自動幫我們產生的函式,這個函式的工作就是幫我們作字彙剖析,一直到結束後才會返回。返回之後,我們再把計算的字元數、字數以及行數列印到畫面上。
看過這個簡單的範例之後,是不是對於lex是如何運作以及怎麼使用lex有點概念了。
yacc
yacc必須搭配lex一起使用,因為yacc主要的工作是作語法分析,而構成語法句子的token是由lex負責分析比對。和上一節同樣,我們透過一個簡單的範例來學習如何使用yacc。這個範例我們要作的是,能從輸入串流中的每一行文字裡讀取0個或1個以上的數字,如果有超過1個以上的數字,則每個數字需以逗號分開,最後再把所有數字相加的結果列印到畫面上,直到結束輸入為止。
首先我們第一步驟是使用EBNF表示式把規則寫出來。
S := INTEGER (',' INTEGER)*因為yacc的樣式區塊裡的樣式使用的是BNF表示式,所以我們要把上述的規則改寫為BNF表示式。integers := INTEGER | INTEGER ',' integers有了BNF表示式之後,我們就可以寫出用來給yacc看的定義檔了。定義檔的格式和lex定義檔的格式類似,底下我們列出這個範例的yacc定義。
%{
int yylex(void);
%}
%token INTEGER
%%
lines
:
| lines integers '\n' { printf(" = %d\n", $2); }
;
integers
: INTEGER { $$ = $1; }
| INTEGER ',' integers { $$ = $1 + $3; }
;
%%
int main(void)
{
yyparse();
return 0;
}上表是yacc定義檔,我們直接看樣式區塊部份。列表中我們寫了二條樣式,第二條integers也就是我們前面寫下來的BNF表示式。除此外我們再另外加了一條規則lines,這條規則可以讓我們在執行測試的時候可以連續測試多行的資料,而不必每次測完一行資料就需要再重新執行程式。我們現在要注意的是在樣式的右側的動作程式碼。和lex定義檔裡的動作程式碼一樣,我們統一使用大括號將動作指令括起來。在動作程式碼裡面我們可以看到像$1、$2還有$$這樣奇怪的東西。在動作程式碼裡的這幾個符號是對應到樣式裡面的符號值,從左邊開始算來,第一個符號叫作$1,第二個叫$2,依此類推。而樣式左側,也就是樣式冒號的左側值則以$$表示。
因此,我們在lines樣式裡的$2就對應integers。預設情形下,符號值的型別是整數,當然我們也可以使用其它型別的符號值,不過這不是我們要談的重點,有興趣的話請參考lex/yacc相關書籍資料。lex定義檔內容我們就不再表列出來,可以自行參考範例內容。
實作
了解lex及yacc的使用後,我們就可以使用lex及yacc來協助我們實作算式計算機了。以下表列出yacc的算式計算機實作定義檔內容。
%{
#define YYSTYPE double
extern int yylex();
%}
%token NUMBER
%%
lines
:
| lines expression '\n' { printf(" = %lf\n", $2); }
;
expression
: term { $$ = $1; }
| expression '+' term { $$ = $1 + $3; }
| expression '-' term { $$ = $1 - $3; }
;
term
: factor { $$ = $1; }
| term '*' factor { $$ = $1 * $3; }
| term '/' factor { $$ = $1 / $3; }
;
factor
: NUMBER { $$ = $1; }
| group { $$ = $1; }
;
group
: '(' expression ')' { $$ = $2; }
;
%%
int main(int argc, char** argv)
{
yyparse();
return 0;
}下表是lex定義內容。%{
#include "y.tab.h"
%}
%%
[0-9]+"."[0-9]+ { sscanf(yytext,"%lf",&yylval); return NUMBER; }
[0-9]+ { sscanf(yytext,"%lf",&yylval); return NUMBER; }
[ \t] ;
[\n] { return '\n'; }
. { return yytext[0]; }
%%
int yywrap()
{
return 1;
}
維尼奔逸絕塵,而吾瞠若乎後矣…
回覆刪除這種我看不下去直接跳過的東西
居然可以寫這麼長一串…
維尼想要在good中弄自已的Script來取代Lua嗎?
Lua很好很強大了,不會想要自己弄一套來取代的..
回覆刪除這只是將以前製作的project使用到的相關經驗作一個分享
話說你居然寫的出這種文鄒鄒的詞句,那才是奔逸絕塵啊..
那可請問一下@@為什麼我用你的.l和.y檔下去跑會有錯誤@@
回覆刪除我是用CYGWIN跑得
記得改.h檔的名稱
刪除name="Mcalc"
bison -d -o $name.tab.c $name.y
gcc -c -g -I.. $name.tab.c
flex -o $name.yy.c $name.l
gcc -c -g -I.. $name.yy.c
gcc -o $name $name.tab.o $name.yy.o -lfl -ly
./$name < input.txt
請問是什麼錯誤?
回覆刪除在cygwin下,請用flex取代lex,用bison取代yacc
在GCC的時候好像yylex有問題@@
回覆刪除試試用cc,不要用gcc
回覆刪除那個我也碰到同樣問題 "yyparse" 錯誤
回覆刪除不管gcc 還是 cc 都一樣
請問錯誤訊息是??
回覆刪除如果沒按照你說的用bison而用yacc -d 檔名.y
回覆刪除在gcc -c y.tab.c -o y.tab.o 時候 會出現
in function 'yyparse':
檔名.y:11:6 warning: incompatible implicit declaration of built-in funtion 'printf' 的錯誤
我把lines 那段砍掉缺能通過 表示printf 那邊應該有問題?
我用bison通過了之後在 gcc lex.yy.o y.tab.o -o yacc指令之後出現
y.tab.o:y.tab.c:undefined reference to'_yyerror'
y.tab.o:y.tab.c:undefined reference to'_yyerror'
collect2:id returned 1 exit status
真象大白了,不好意思,請加上
回覆刪除void yyerror(char* msg)
{
printf("error\n") ;
exit(1) ;
}
所以少了error 的判斷!?
回覆刪除不對,這是少了一個叫作yyerror的function,錯誤訊息裡已經說的很清楚了! undefined reference to'_yyerror',補上去就可以了
回覆刪除Sorry,這又是我的一個筆誤..
根據你+的指令 除了原的錯誤以外還增加了更多的錯誤
回覆刪除我把檔案上傳了,試試看吧
回覆刪除http://good-ed.smallworld.idv.tw/forum/download/file.php?id=28
請問那個makefile 怎麼用?!
回覆刪除我對LINUX 類的東西不熟
直接在目錄下,輸入make即可
回覆刪除make程式需要事先安裝好
>make
回覆刪除>flex test.l
>yacc -d test.y
>gcc -c lex.yy.c -o lex.yy.o
>gcc -c y.tab.c -o y.tab.o
>gcc lex.yy.o y.tab.o -o yacc
>./yacc < test.txt 這樣順著下輸入!?
請google一下什麼是make..
回覆刪除基本上,只要打make就好了,成功的話就會產生執行檔
我測試了.....只能說 程式還是有錯的
回覆刪除這就奇怪了??在命令列下輸入make後,成功產生執行檔,a.exe後,執行 ./a.exe後就可以輸入算式測試,直到連續enter結束程式
回覆刪除不知道你遇到的問題是什麼,錯誤訊息是?
我上傳了一張圖,內含在cygwin下的操作,參考看看
回覆刪除https://lh6.googleusercontent.com/-TEObg1XDT6k/TvsaJJdCpnI/AAAAAAAAArU/yoEdSgae_tg/s668/58-1.png
我測試完了~ 可以使用...因為我看到的範例都是呼叫text檔案去執行測試XD 所以碰到直接判斷的是第一次XD 中間有些warning我以為有錯所以搞不清楚狀況 哈哈哈哈 感謝大大的回應
回覆刪除讚!
回覆刪除大部份的時候錯誤訊息會提供許多有用的資訊,可以幫助除錯少掉許多試誤的時間
非常感謝,要是早一點看到這篇教學就好了,網路的其他教學光試範例就手軟了Orz,這篇flex bison範例不只看得懂又可以跑,讚
回覆刪除